TL;DR This project evaluates whether machine learning models can outperform a linear benchmark at predicting next-day market direction, testing Logistic Regression, Random Forest, and XGBoost on the S&P 500 and Brent Crude Oil. Thirteen price-based features covering returns, momentum, volatility, and volume were built strictly from data available at each day's close, and models were trained on 2015 to 2022 data before being backtested out of sample from 2022 to 2025, with a 5 basis point one-way transaction cost on every position change.
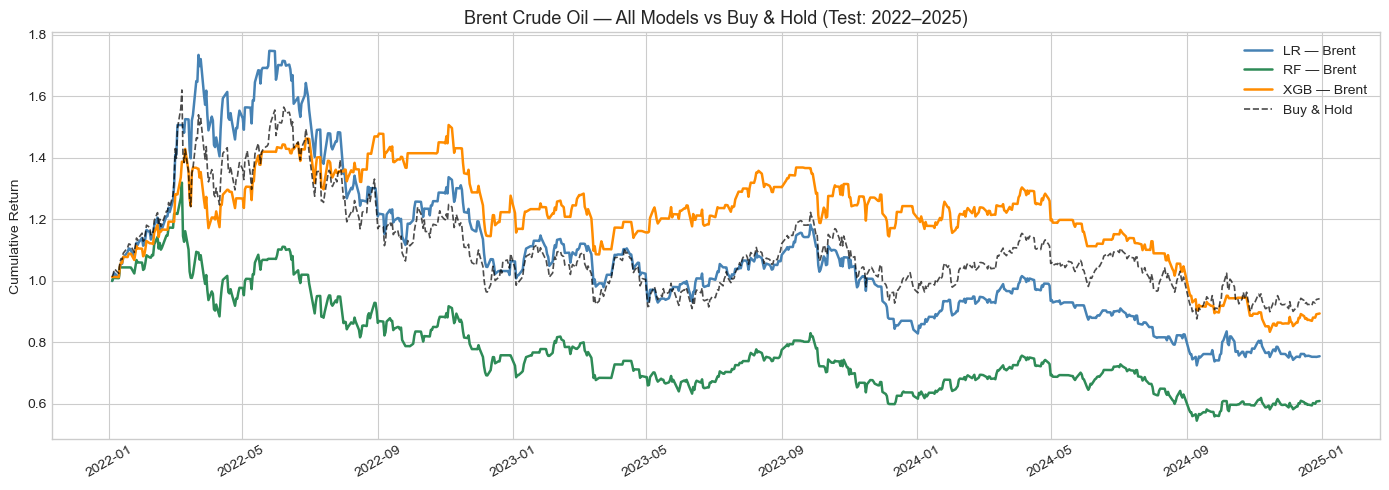
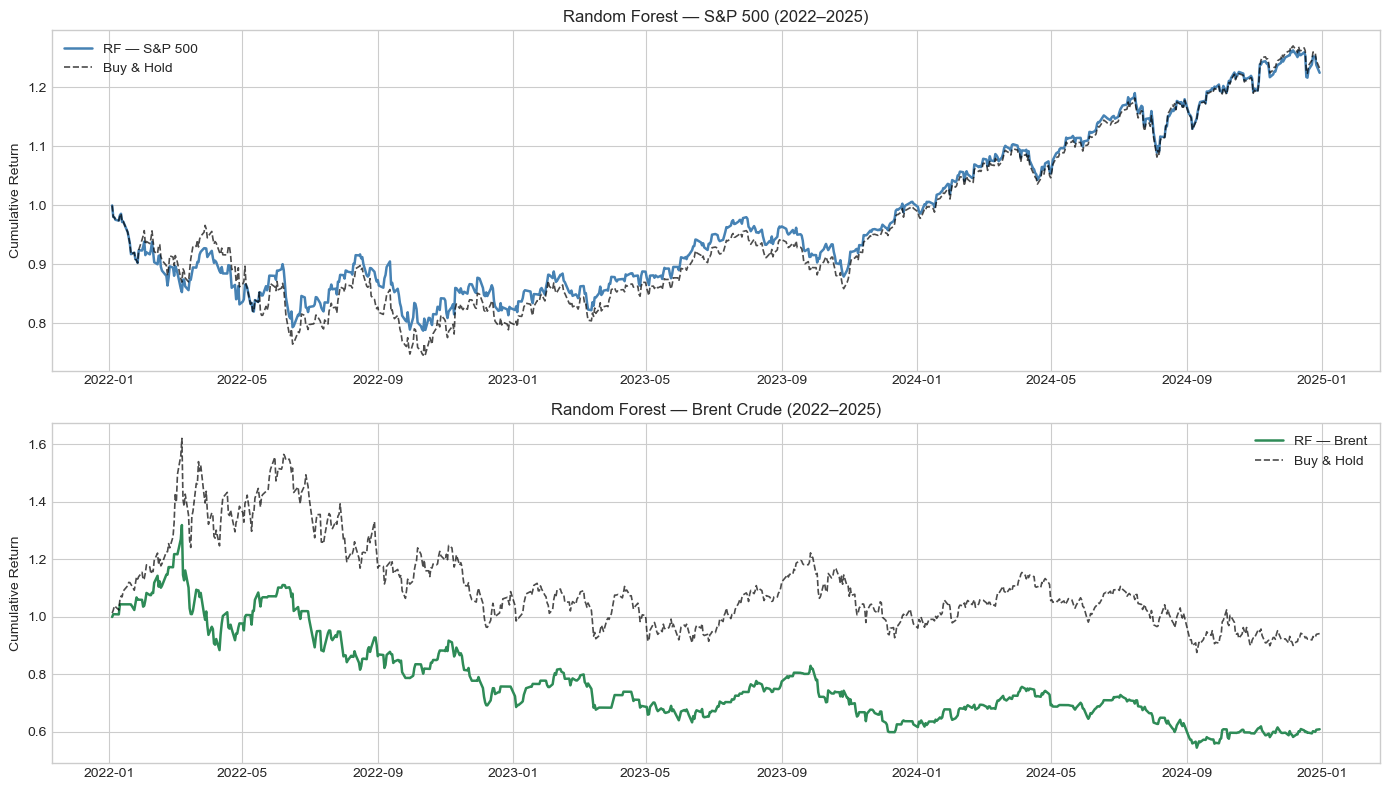
On the S&P 500, Random Forest was the standout, returning 22.41% against Buy and Hold's 23.15%, but with a higher Sharpe ratio of 0.407 and a smaller max drawdown of -21.23%. On Brent Crude, the picture reversed sharply: all three models lost money during the test period, undercut by a geopolitical oil price shock that price-based features alone could not anticipate. The results point to a narrow, transaction-cost-sensitive edge for ML in liquid equity markets, and a clear need for macro and fundamental features when trading commodities.
About the Author

Introduction and Motivation
Financial markets are characterised by a multitude of factors like non-linear dynamics, regime dependence, and complex interaction effects that are poorly captured by classical linear econometric models. While logistic regression gives us interpretability and a clear baseline framework to analyse market performance and direction, its strong functional form assumptions limit its ability to model the higher order feature interactions present in real-world market data. This project aims to evaluate whether machine learning models can generate economically meaningful, risk-adjusted trading signals, and consequently returns, beyond what a linear benchmark can yield.
The study is motivated by Gu, Kelly and Xiu (2020), who demonstrated that machine learning methods produce statistically significant out-of-sample return predictability in equities, and by Fischer and Krauss (2018), who showed similar gains in daily direction prediction. A key practical concern, however, is whether these statistical gains survive the presence of transaction costs and regime changes in a live trading setting. To test this, the project uses two different asset classes: the S&P 500, a highly efficient equity index, and Brent Crude Oil, a commodity driven heavily by geopolitical factors and supply-demand dynamics, providing a richer basis for comparison.
Data and Methodology
Daily OHLCV data was downloaded from Yahoo Finance for both the S&P 500 and Brent Crude from January 2015 to December 2025. The dataset was split into a training period from 2015 to 2022 (approximately 1,740 observations) and an out-of-sample test period from 2022 to 2025 (approximately 752-753 observations). This split ensures the testing period covers a genuinely challenging and distinct market regime: a bear market driven by Federal Reserve rate hikes, an oil price shock from the Russia-Ukraine conflict, and the subsequent recovery
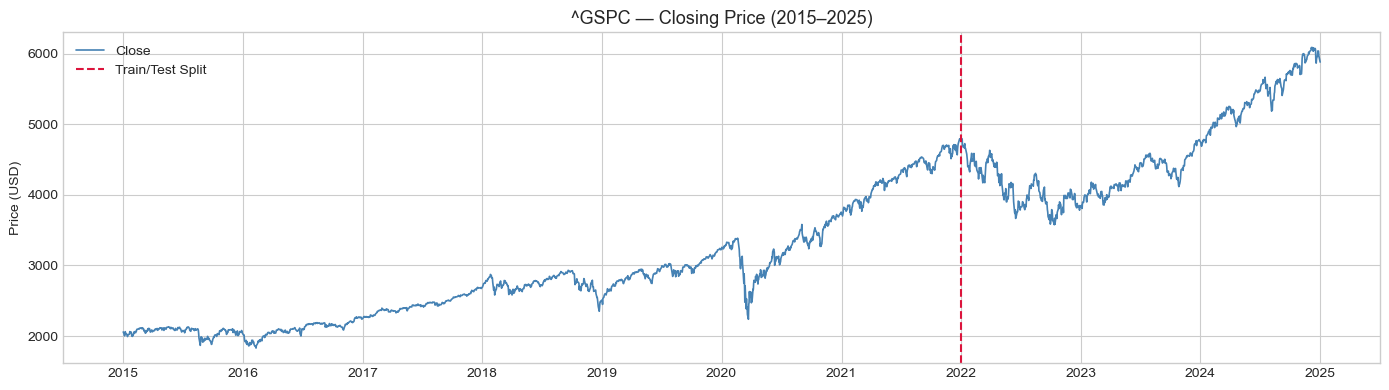
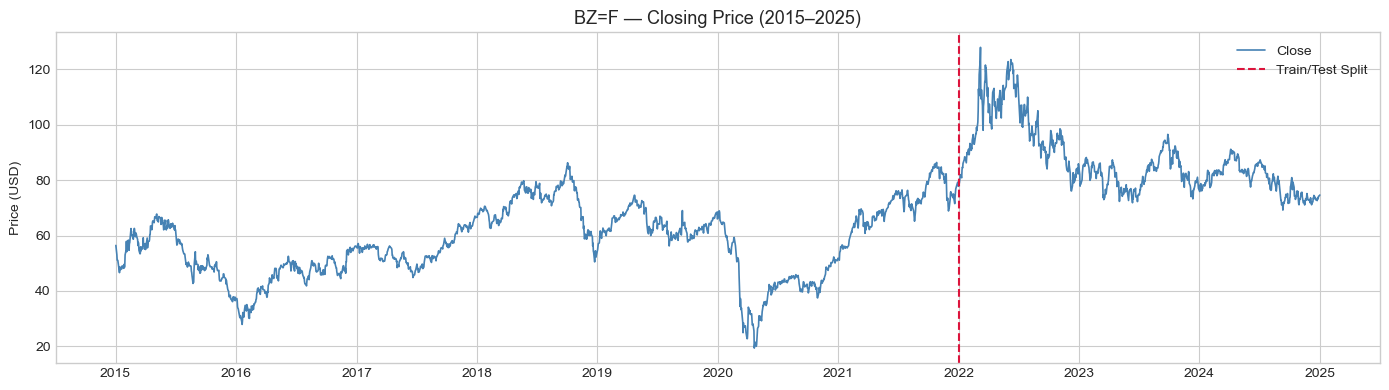
Thirteen price-based features were built using only data available at each day's close, strictly avoiding any look-ahead bias. These include lagged log returns at horizons of 1, 2, 3, 5, 10, and 21 days. Momentum indicators include RSI-14, MACD differential, and 10-day rate of change; volatility measures include 21-day realised volatility, ATR-14, and Bollinger Band width; and a volume ratio relative to the 20-day moving average. The binary target variable is defined as 1 if the next day's return is positive, and 0 otherwise.
Three models were trained and evaluated under identical conditions using an object-oriented Python pipeline: Logistic Regression as the econometric benchmark, Random Forest (300 trees, max depth of 5), and XGBoost (300 estimators, learning rate of 0.05, max depth of 4). A StandardScaler was fitted exclusively on training data and applied to test data without re-fitting, ensuring no information leakage. Each model's signals are converted into a long/flat trading strategy, with a 5 basis point one-way transaction cost applied on every position change.
Results
S&P 500
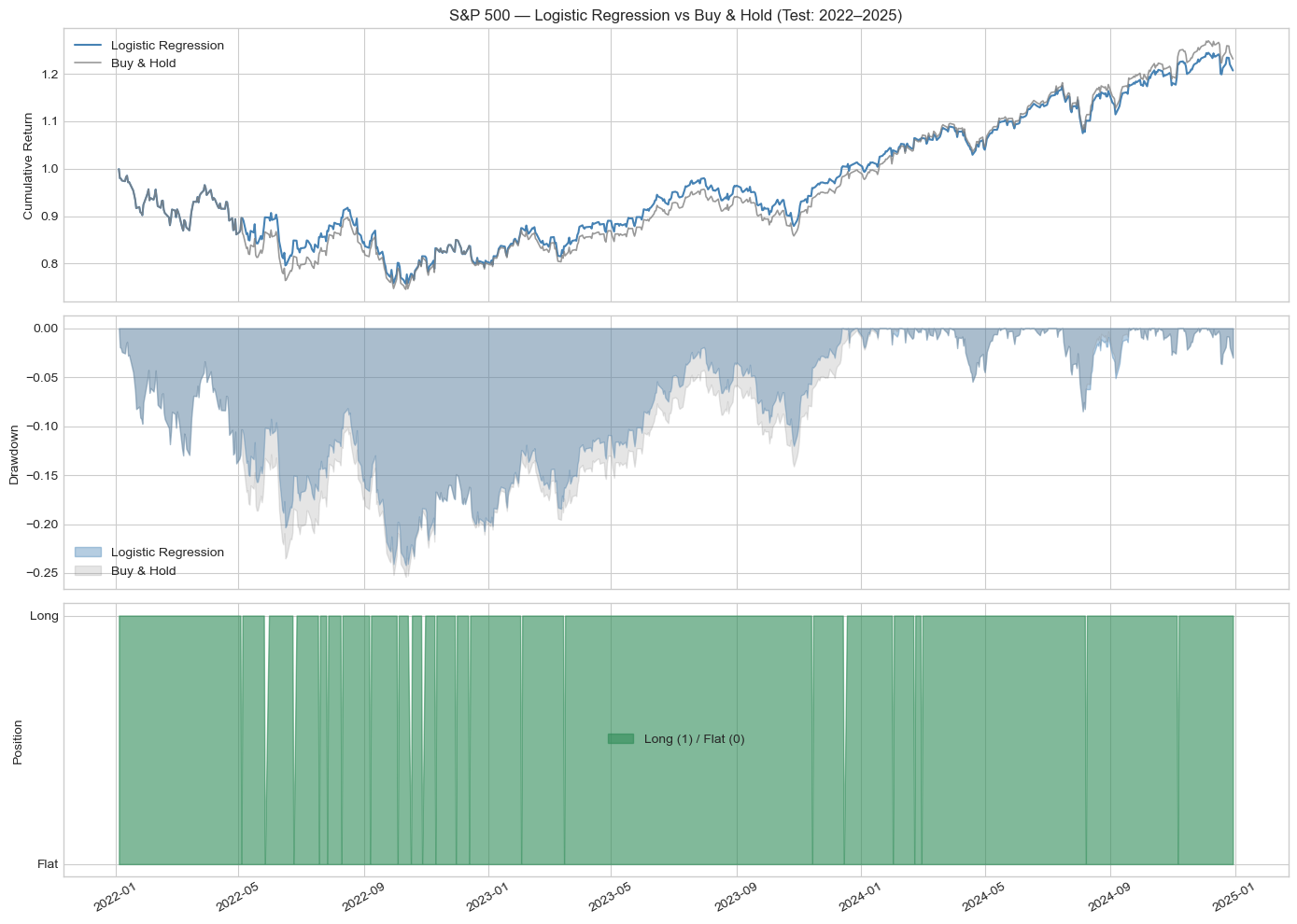
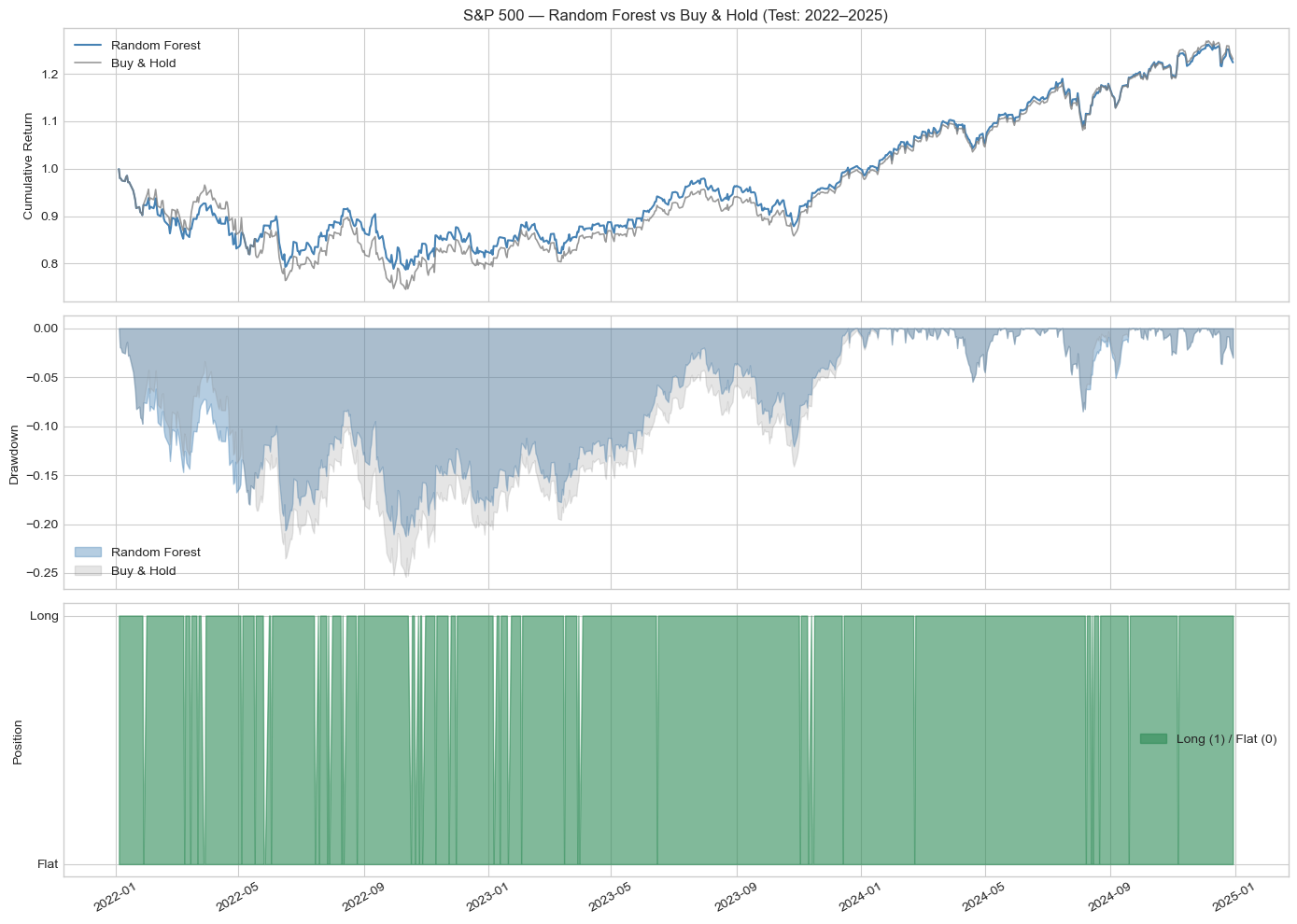
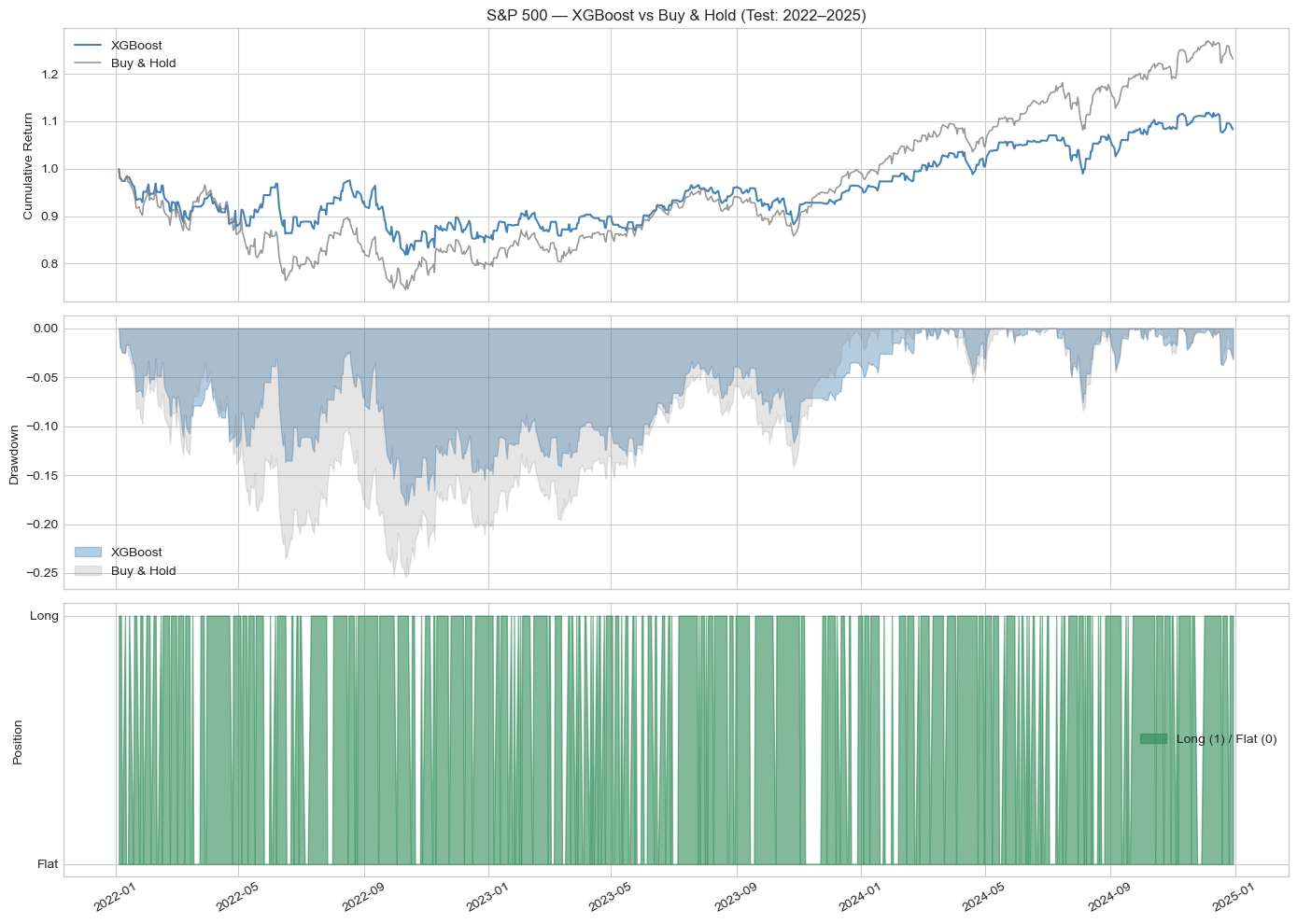
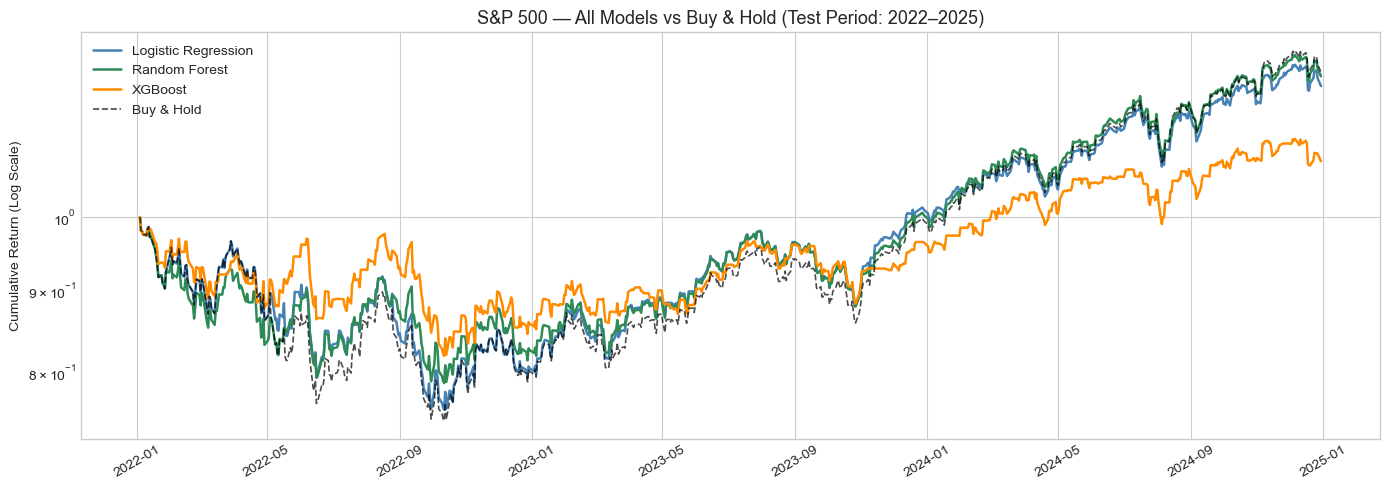
All three models achieved directional accuracy marginally above the 50% baseline, with Random Forest performing best at 51.6% accuracy and an AUC-ROC of 0.4905. In the backtest, Random Forest generated a total return of 22.41% versus Buy and Hold's 23.15%, with a superior Sharpe ratio of 0.407 against 0.399. Max drawdown was also smaller at -21.23% versus -25.38%, and its Calmar ratio of 0.331 exceeded the benchmark's 0.285, indicating a better return per unit of drawdown risk. Logistic Regression came a close second, earning 20.71% with a Sharpe of 0.366 from just 44 trades. XGBoost, despite similar statistical accuracy, significantly underperformed: 270 trades eroded returns through transaction costs, producing a total return of only 8.31%.
| Metric | LR | RF | XGBoost | Buy & Hold |
|---|---|---|---|---|
| Total Return | 20.71% | 22.41% | 8.31% | 23.15% |
| Ann. Return | 6.52% | 7.02% | 2.72% | 7.24% |
| Sharpe Ratio | 0.366 | 0.407 | 0.174 | 0.399 |
| Max Drawdown | -24.19% | -21.23% | -18.10% | -25.38% |
| Calmar Ratio | 0.269 | 0.331 | 0.150 | 0.285 |
| No. of Trades | 44 | 84 | 270 | 1 |
Table 1: S&P 500 backtest performance, net of 5bps transaction cost, test period 2022-2025.
Brent Crude {#brent-crude}
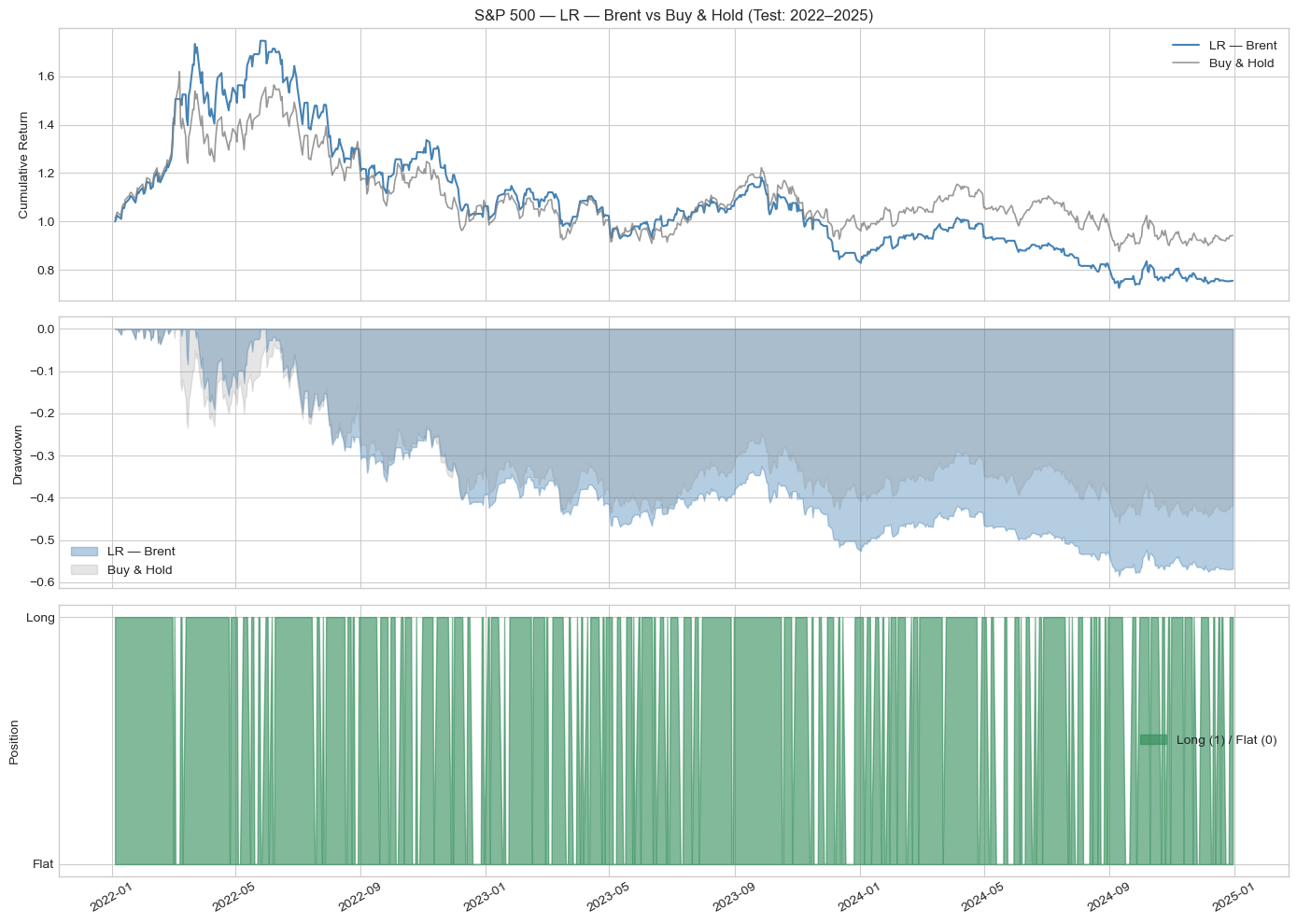
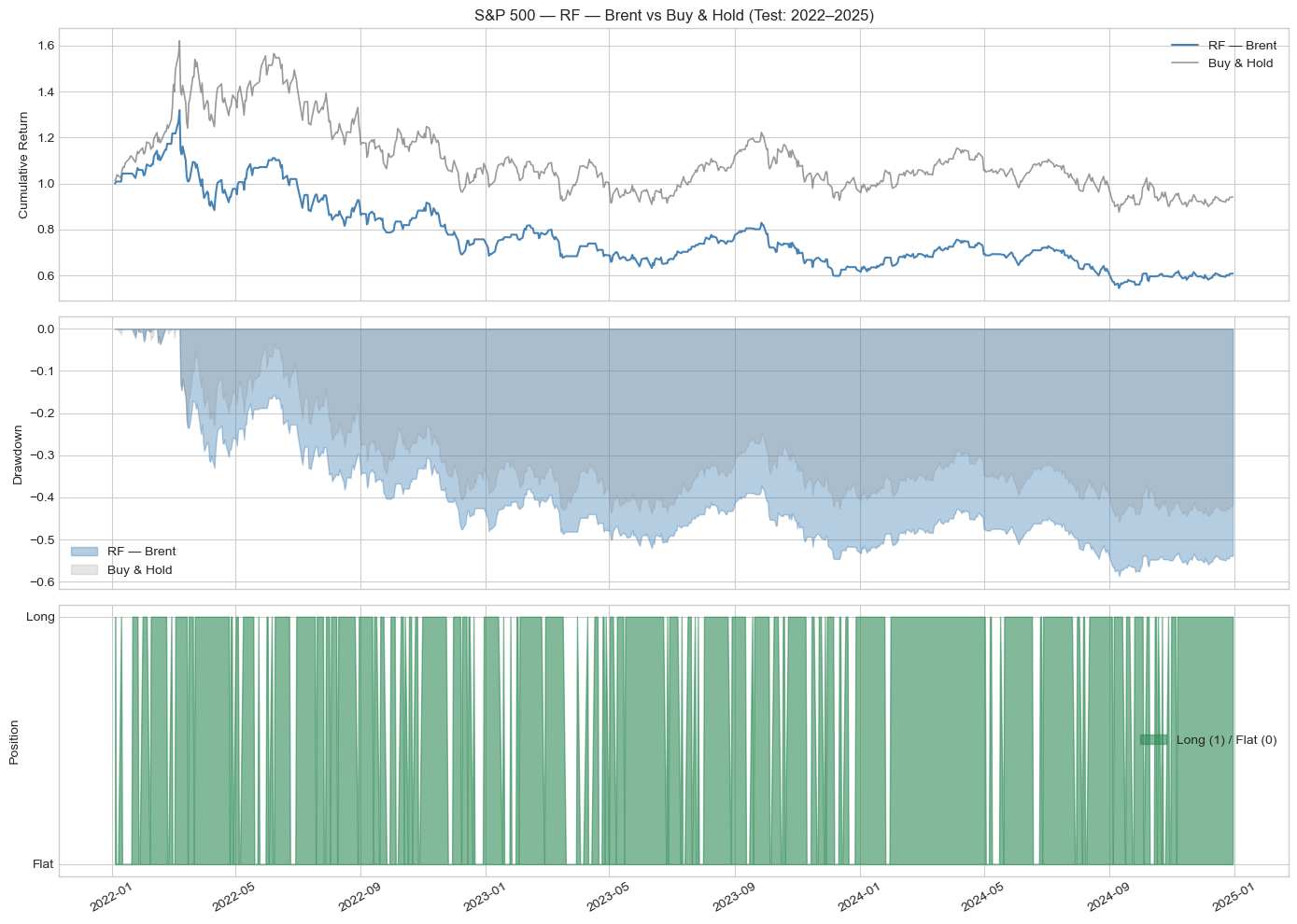
Results on Brent Crude were markedly different and constitute the most important finding of this study. All three models lost money during the testing period, despite the Brent Buy and Hold strategy itself losing only 5.81%. XGBoost was the least-bad performer with a total return of -10.63% (Sharpe of -0.137), while Logistic Regression lost 24.53% and Random Forest lost 39.08%. Notably, XGBoost achieved the highest statistical performance on Brent, with an accuracy of 51.39% and an AUC-ROC of 0.5196, the only model across both assets to exceed an AUC of 0.50, yet this did not translate into net positive trading returns.
The root cause is clear from the equity curve: Brent spiked dramatically to approximately $130 a barrel in early 2022 following the Russia-Ukraine conflict, then entered a prolonged decline back to $70-75 by the end of 2025. This geopolitical shock was fundamentally unpredictable from price-based features alone. Models trained on 2015-2022 data had no exposure to this type of regime, and the long/flat strategy repeatedly signalled long trades in a declining market. High trade counts, ranging from 173 to 300, further amplified the losses through excessive transaction costs.
| Metric | LR | RF | XGBoost | Buy & Hold |
|---|---|---|---|---|
| Total Return | -24.53% | -39.08% | -10.63% | -5.81% |
| Ann. Return | -9.00% | -15.30% | -3.70% | -1.99% |
| Sharpe Ratio | -0.298 | -0.524 | -0.137 | -0.056 |
| Max Drawdown | -58.52% | -58.67% | -44.65% | -45.94% |
| No. of Trades | 205 | 173 | 300 | 1 |
Table 2: Brent Crude backtest performance, net of 5bps transaction cost, test period 2022-2025.
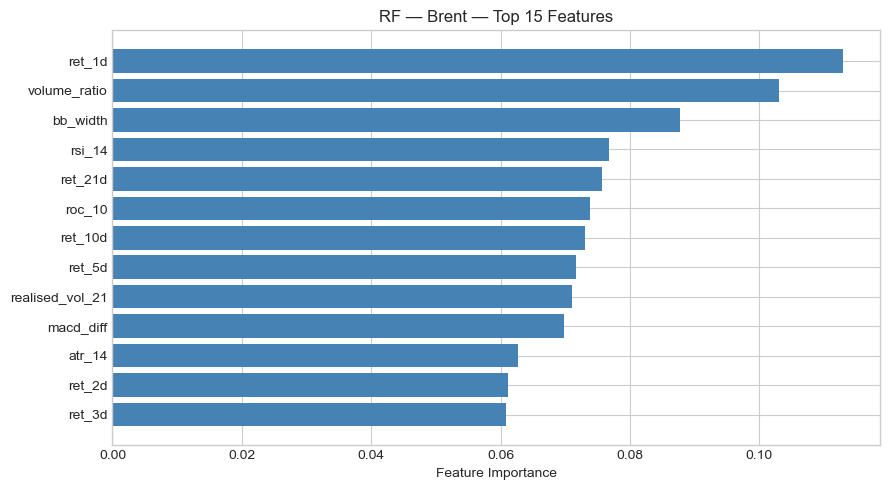
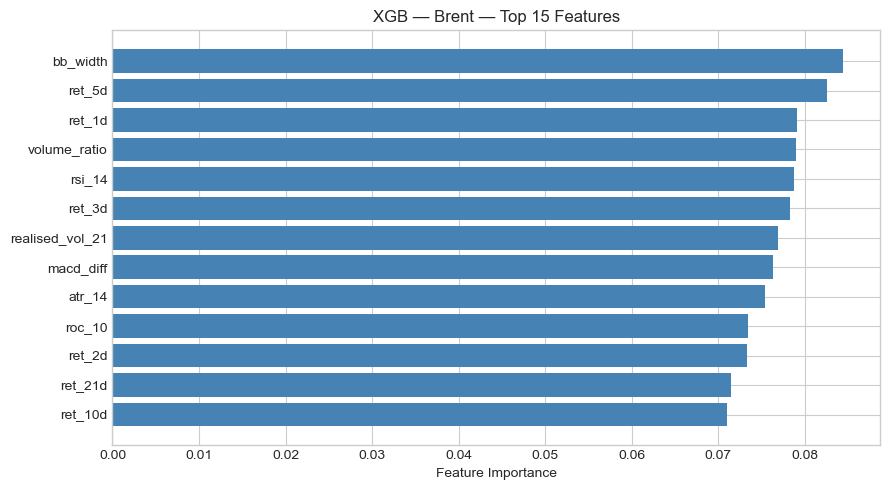
Feature Importance
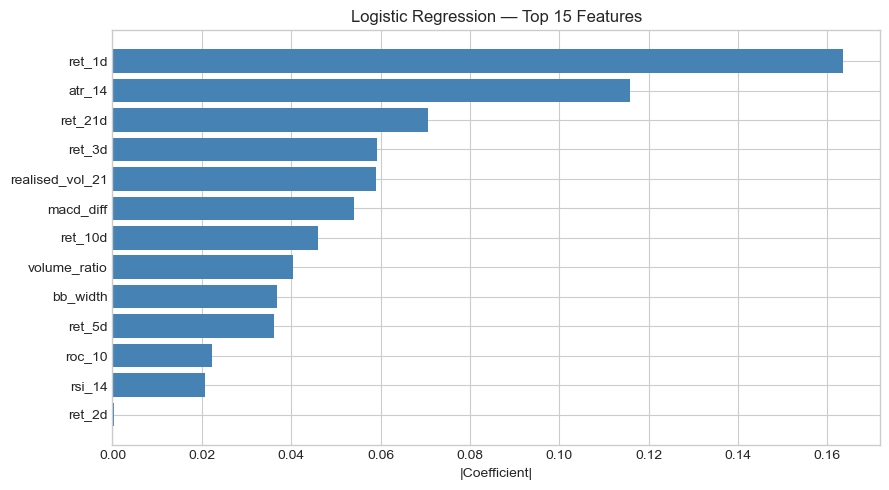
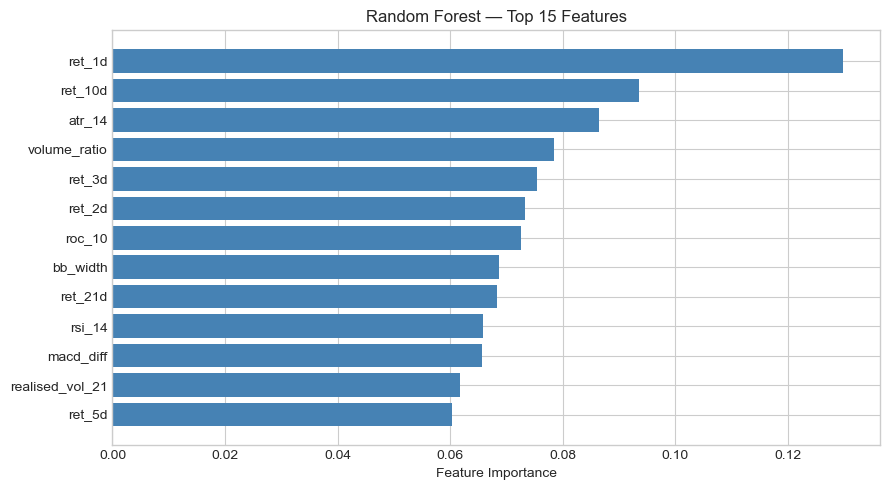
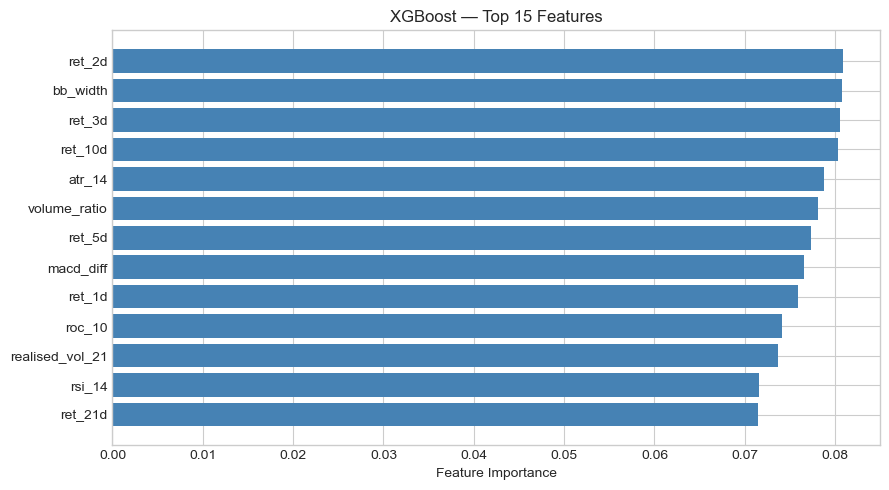
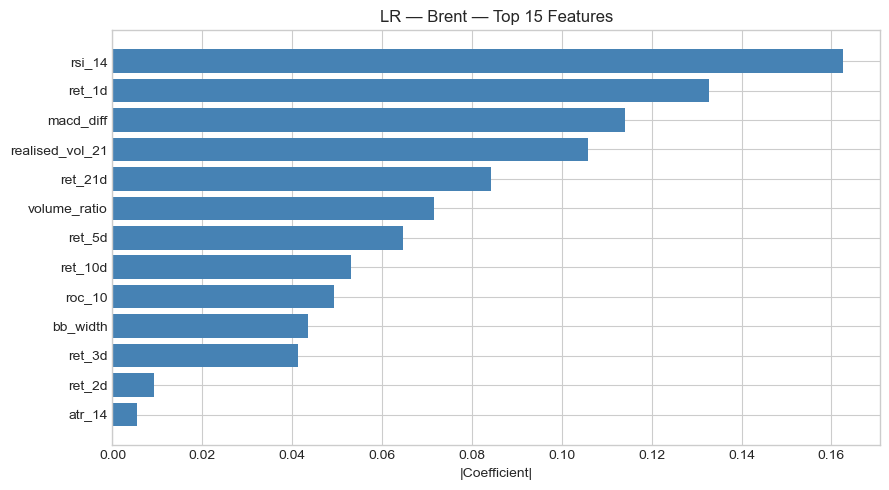
Across both assets, short-term lagged returns, particularly ret_1d, consistently ranked among the most important features, pointing to short-horizon momentum effects. On the S&P 500, ATR-14 (volatility) was the second most important feature for Logistic Regression, while Random Forest also weighted ret_10d and volume_ratio highly. On Brent, the feature importance profile shifted: RSI-14 topped Logistic Regression, and Bollinger Band width dominated XGBoost, suggesting that volatility expansion signals carry more predictive power in commodities than in equities. This fits an intuitive lens, since oil markets are characterised by sharper volatility regimes tied to supply events, and wider Bollinger Bands signal a breakout environment where directional prediction may be more feasible.
Discussion and Limitations
The results support a nuanced conclusion: machine learning does add marginal, measurable value over linear models in liquid equity markets, but that value is small, regime-dependent, and highly sensitive to transaction costs. Random Forest on the S&P 500 was the only model to exceed Buy and Hold on a risk-adjusted basis, yet its Sharpe advantage over the benchmark was just 0.008. These marginal gains are consistent with Gu, Kelly and Xiu (2020), who found incremental but persistent ML improvements in highly efficient markets. Walk-forward validation reinforced this point: Logistic Regression's accuracy improved to 53.47% under rolling retraining, but returns fell to just 7.95% versus Buy and Hold's 26.89%, showing that even accurate signals deteriorate once the model has to adapt to changing regimes in real time.
The results from Brent expose the most critical limitation of this approach: purely price-based features are insufficient for commodities. Oil prices are fundamentally driven by OPEC production decisions, geopolitical events, and macroeconomic demand, none of which are captured by lagged returns or technical indicators. Incorporating macro features such as inventory levels, USD strength, or geopolitical risk indices would likely improve commodity performance substantially. Transaction costs are also a major limitation: XGBoost's tendency to trade frequently, at 270 trades on the S&P 500 and 300 on Brent, suggests that a probability threshold above 0.55 for signal generation, or a minimum holding period constraint, would reduce turnover and improve net performance.
References
Gu, S., Kelly, B., & Xiu, D. (2020). Empirical asset pricing via machine learning. The Review of Financial Studies, 33(5), 2223–2273. Fischer, T., & Krauss, C. (2018). Deep learning with long short-term memory networks for financial market predictions. European Journal of Operational Research, 270(2), 654–669. Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32. Chen, T., & Guestrin, C. (2016). XGBoost: A scalable tree boosting system. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 785–794.
Downloads
Download the Complete Project and Python Notebook below:
Conclusion
This project demonstrates that machine learning models can generate marginal but real improvements over conventional logistic regression in predicting short-term equity market direction on indices like the S&P 500. Random Forest proved the most robust model, achieving a higher Sharpe ratio and a lower maximum drawdown than a passive Buy and Hold strategy over the 2022-2025 test period. However, these gains are small and do not extend to commodity markets, where geopolitical shocks render price-based ML models ineffective. The study underscores that model design must be elastic, accounting for transaction costs, regime sensitivity, and the fundamental information content available in the chosen feature set. Future work should incorporate macro and alternative data, apply probabilistic position sizing mechanisms, and extend the asset universe to test more robust cross-asset generalisability with greater rigour.
Frequently Asked Questions
Q1. What is the main objective of this project? The project tests whether Logistic Regression, Random Forest, and XGBoost can generate economically meaningful, risk-adjusted trading signals beyond a linear benchmark, using the S&P 500 and Brent Crude Oil as two contrasting test cases.
Q2. Why compare an equity index against a commodity? The S&P 500 represents a highly efficient, liquid equity market, while Brent Crude is heavily influenced by geopolitical and supply-demand shocks. Testing both reveals whether ML gains generalise across asset classes or are specific to market structure.
Q3. What features were used as model inputs? Thirteen price-based features built strictly from data available at each day's close: lagged log returns at six horizons, momentum indicators (RSI-14, MACD differential, 10-day rate of change), volatility measures (realised volatility, ATR-14, Bollinger Band width), and a 20-day volume ratio.
Q4. How were the three models configured? Logistic Regression served as the econometric benchmark, Random Forest used 300 trees with a max depth of 5, and XGBoost used 300 estimators with a learning rate of 0.05 and a max depth of 4. All three were trained on 2015-2022 data and tested out of sample from 2022-2025.
Q5. Which model performed best on the S&P 500, and why? Random Forest, with a 22.41% total return, a Sharpe ratio of 0.407, and a smaller drawdown than Buy and Hold. Its edge came from balancing reasonable accuracy with a moderate trade count of 84, avoiding the transaction cost drag that hurt XGBoost.
Q6. Why did all three models lose money on Brent Crude? Brent spiked to roughly $130 a barrel after the Russia-Ukraine conflict before declining steadily through 2025. This geopolitical shock was not predictable from price-based features alone, so the long/flat strategy kept signalling long positions in a falling market.
Q7. What does an AUC-ROC just above 0.50 actually mean here? It means the model's ability to separate up days from down days is only marginally better than a coin flip. XGBoost's 0.5196 AUC on Brent was the best result across both assets, yet still translated into a net loss once trading costs were applied.
Q8. How did walk-forward validation change the results? Under rolling retraining, Logistic Regression's accuracy improved to 53.47%, but returns fell to 7.95% against Buy and Hold's 26.89%. This shows that even a more accurate signal can underperform once the model must continuously adapt to a shifting regime.
Q9. What are the main limitations of this project? The reliance on purely price-based features, which misses macro drivers like OPEC decisions and USD strength; sensitivity to transaction costs, especially for high-turnover models like XGBoost; and a long/flat structure that cannot express a short view during sustained downtrends.
Q10. What improvements are planned for future work? Incorporating macro and alternative data such as inventory levels and geopolitical risk indices, applying probabilistic position sizing instead of a binary long/flat rule, raising the signal threshold or adding a minimum holding period to cut turnover, and extending the asset universe for broader cross-asset testing.
Next Steps
If you'd like to go deeper into machine learning for market direction prediction, here are concise resources to guide your build:
Start with the foundations in Machine Learning Logistic Regression: Python, Trading and More, then move into tree-based models with Random Forest Algorithm in Trading Using Python and Introduction to XGBoost in Python.
For validation methodology, read Walk-Forward Optimization: How It Works, Its Limitations, and Backtesting Implementation and the follow-up walkthrough, Implement Walk-Forward Optimization with XGBoost for Stock Price Prediction in Python.
See how a similar ML-plus-technical-indicator approach plays out on another commodity in Predicting Stock Trends Using Technical Analysis and Random Forests and the Brent oil-focused Mid-Frequency Oil Futures Trading Strategy Using Candlestick Patterns and Machine Learning | EPAT Project. Browse Algorithmic Trading Projects to shortlist your next build.
For a structured, hands-on learning path, explore Quantra's Machine Learning & Deep Learning in Trading learning track.
Looking for a structured, hands-on path guided by expert practitioners?
EPAT offers a practitioner-led curriculum in Python-based algorithmic trading. You'll learn core strategies you can adapt to higher-frequency settings, work with broker APIs such as Alpaca, and build mentored live projects. Learn more or register here for our Executive Programme in Algorithmic Trading (EPAT).
Schedule an EPAT counselling call
To understand if EPAT is the right choice for you, talk to one of our specialists who have counselled thousands of learners over the past decade and helped them make the right career decision.