
By Varun Divakar and Rekhit Pachanekar
Let us get to the topic directly. Exactly what is forward propagation in neural networks? Well, if you break down the words, forward implies moving ahead and propagation is a term for saying spreading of anything. forward propagation means we are moving in only one direction, from input to the output, in a neural network. Think of it as moving across time, where we have no option but to forge ahead, and just hope our mistakes don’t come back to haunt us.
Now, if you are thinking that Neural networks have a very low usefulness in trading, well we have to tell you that almost all the quant hedge funds have moved from neural networks to deep learning and AI to somehow keep an edge over the others. From Renaissance tech to Two Sigma, neural networks are being utilized in unprecedented ways.
Now, before we start with an example of forward propagation, let us see the topics being covered in this blog.
- A brief history of Neural Networks
- What is forward propagation in Neural Networks?
- Components of forward propagation model
- Applications of forward propagation
A brief history of Neural Networks
We have tried to understand how humans work since time immemorial. In fact, even philosophy is in effect, trying to understand the human thought process. But it was only in recent years that we started making progress on understanding how our brain operates. And this is where conventional computers differ from humans.
You see, while we can develop an algorithm to solve a problem, we have to make sure we have taken into account all sorts of probabilities. Whereas, when it comes to humans, we might start off with limited or incomplete information, but we ‘learn’ and solve problems faster and with greater accuracy. Well, at least that’s what everyone says!
Thus, we started to research and develop artificial brains, which are actually called neural networks now.
The basic structure in the neural network is the perceptron, which is modelled after the neurons in our cells.

There are inputs to the neuron marked with yellow circles, and the neuron emits an output signal after some computation.
The input layer resembles the dendrites of the neuron and the output signal is the axon. Each input signal is assigned a weight, wi. This weight is multiplied by the input value and the neuron stores the weighted sum of all the input variables.
An activation function is then applied to the weighted sum, which results in the output signal of the neuron.
A popular example of neural networks is the image recognition software which can identify faces and is able to tag the same person in different lighting conditions as well. That being said, let us understand forward propagation in more detail now.
What is forward propagation in Neural Networks?
One of the first neural networks used the concept of forward propagation. I’ll try to explain forward propagation with the help of a simple equation of a line.
We all know that a line can be represented with the help of the equation: y = mx + b
Where y is the y coordinate of the point, m is the slope, x is the x coordinate and b is the y-intercept i.e. the point at which the line crosses the y-axis.
But why are we jotting the line equation here? This will help us later on when we understand the components of a neural network in detail.
Remember how we said neural networks are supposed to mimic the thinking process of humans. Well, let’s just assume that we do not know the equation of a line, but we do have a graph paper and draw a line randomly on it.
For the sake of this example, you drew a line through the origin and when you saw the x and y coordinates, they looked like this:

This looks familiar. If I asked you to find the relation between x and y, you would directly say it is y = 3x. But let us go through the process of how forward propagation works.
We will assume here x is the input and y is the output.
The first step here is the initialization of the parameters. We will guess that y must be a multiplication factor of x. So we will assume that y = 5x and see the results then. Let us add this to the table and see how far we are from the answer.

Note that taking the number 5 is just a random guess and nothing else. We could have taken any other number here. I should point out that here we can term 5 as the weight of the model.
All right, this was our first attempt, now we will see how close (or far) we are from the actual output.
One way to do that is to use the difference of the actual output and the output we calculated. We will call this the error. Here, we aren’t concerned with the positive or negative sign and hence we take the absolute difference of the error. Thus, we will update the table now with the error.

If we take the sum of this error, we get the value 30. But why did we total the error? Since we are going to try multiple guesses to come to the closest answer, we need to know how close or how far we were from the previous answers. This helps us refine our guess and calculate the correct answer.
Wait. But if we just add up all the error values, it feels like we are giving equal weightage to all the answers. Shouldn’t we penalise the values which are way off the mark? For example, 10 here is too high than 2. It is here that we introduce the somewhat famous “Sum of squared Errors” or SSE for short. In SSE, we square all the error values and then add them. Thus, the error values which are very high get exaggerated and thus helps us in knowing how to proceed further.
Let’s put these values in the table below.

Now the SSE for the weight 5 (Recall that we assumed y = 5x), is 145. We call this the loss function. The loss function is important to understand the efficiency of the neural network and also helps us when we incorporate backpropagation in the neural network.
All right, so far we understood the principle of how the neural network tries to learn. We have also seen the basic principle of the neuron. Let us now understand forward propagation in the neural network itself.
Components of forward propagation model

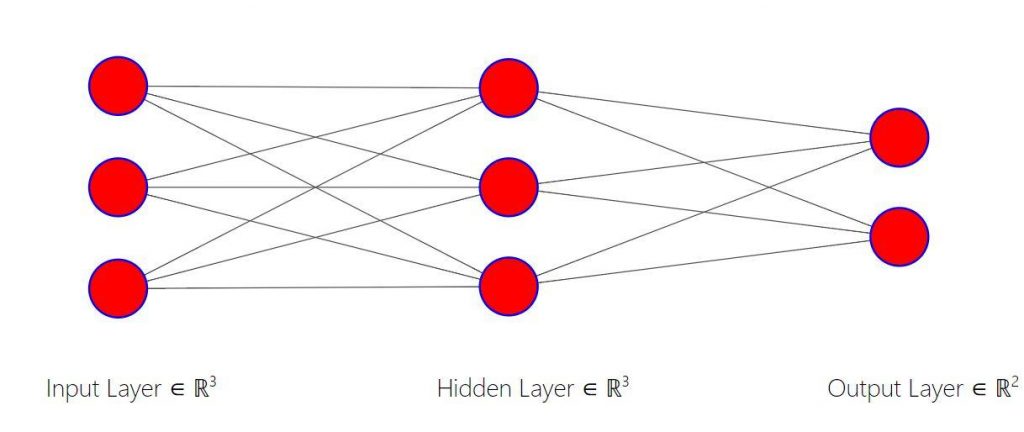
In the above diagram, we see a neural network consisting of three layers. The first and the third layer are straightforward, input and output layers. But what is this middle layer and why is it called the hidden layer?
Now, in our example, we had just one equation, thus we have only one neuron in each layer.
Nevertheless, the hidden layer consists of two functions:
Pre-activation function : The weighted sum of the inputs is calculated in this function.Activation function : Here, based on the weighted sum, an activation function is applied to make the network non-linear and make it learn as the computation progresses. The activation function uses bias to make it non-linear.
That’s all there is to know about forward propagation in Neural networks. But wait! How can we apply this model in trading? Let’s find out below.
Applications of forward propagation
In this example, we will be using a 3-layer network (with 2 input units, 2 hidden layer units, and 2 output units). The network and parameters (or weights) can be represented as follows.
Let us say that we want to train this neural network to predict whether the market will go up or down. For this, we assign two classes Class 0 and Class 1.
Here, Class 0 indicates the datapoint where the market closes down, and conversely, Class 1 indicates that the market closes up. To make this prediction, a train data(X) consisting of two features x1, and x2.
Here x1 represents the correlation between the close prices and the 10- day simple moving average (SMA) of close prices, and x2 refers to the difference between the close price and the 10-day SMA.
In this example below, the datapoint belongs to the class 1. The mathematical representation of the input data is as follows:
X = [x1, x2] = [0.85,.25] y= [1]
Example with two data points:
$$ X = \begin{bmatrix} x_{11} & x_{12} \\ x_{22} & x_{22} \\ \end{bmatrix} = \begin{bmatrix} 0.85 & 0.25 \\ 0.71 & 0.29 \\ \end{bmatrix} $$$$ Y = \begin{bmatrix} y_1 \\ y_2 \\ \end{bmatrix} = \begin{bmatrix} 1 \\ 2 \\ \end{bmatrix} $$The output of the model is categorical or a discrete number. We need to convert this output data also into a matrix form. This enables the model to predict the probability of a datapoint belonging to different classes. When we make this matrix conversion, the columns represent the classes to which that example belongs, and the rows represent each of the input examples.
$$ Y = \begin{bmatrix} y_1 \\ y_2 \\ \end{bmatrix} = \begin{bmatrix} 0 & 1 \\ 1 & 0 \\ \end{bmatrix} $$In the matrix y, the first column represents class 0 and second column represents class 1. Since our example belongs to Class 1, we have 1 in the second column and zero in the first.

This process of converting discrete/categorical classes to logical vectors/ matrix is called One-Hot Encoding. It's sort of like converting the decimal system (1,2,3,4....9) to binary (0,1,01,10,11). We use one-hot encoding as the neural network cannot operate on label data directly. They require all input variables and output variables to be numeric.
In a neural network learning, apart from the input variable, we add a bias term to every layer other than the output layer. This bias term is a constant, mostly initialized to 1. The bias enables moving the activation threshold along the x-axis.


When the bias is negative the movement is made to the right side, and when the bias is positive the movement is made to the left side. So a biased neuron should be capable of learning even such input vectors that an unbiased neuron is not able to learn. In the dataset X, to introduce this bias we add a new column denoted by ones, as shown below.
$$ X = \begin{bmatrix} x_0 & x_1 & x_2 \\ \end{bmatrix} = \begin{bmatrix} 1 & 0.85 & 0.25 \\ \end{bmatrix} $$Let us randomly initialize the weights or parameters for each of the neurons in the first layer. As you can see in the diagram we have a line connecting each of the cells in the first layer to the two neurons in the second layer. This gives us a total of 6 weights to be initialized, 3 for each neuron in the hidden layer. We represent these weights as shown below.
$$ Theta_1 = \begin{bmatrix} 0.1 & 0.2 & 0.3 \\ 0.4 & 0.5 & 0.6 \\ \end{bmatrix} $$Here, Theta1 is the weights matrix corresponding to the first layer.

The first row in the above representation shows the weights corresponding to the first neuron in the second layer, and the second row represents the weights corresponding to the second neuron in the second layer. Now, let’s do the first step of the forward propagation, by multiplying the input value for each example by their corresponding weights which is mathematically show below.
Theta1 * X
Before we go ahead and multiply, we must remember that when you do matrix multiplications, each element of the product, X*Theta, is the dot product sum of the row in the first matrix X with each of the columns of the second matrix Theta1.
When we multiply the two matrices, X and Theta1, we are expected to multiply the weights with the corresponding input example values. This means we need to transpose the matrix of example input data, X, so that the matrix will multiply each weight with the corresponding input correctly.
$$ X_t = \begin{bmatrix} 1 \\ 0.85 \\ 0.25 \\ \end{bmatrix} $$z2 = Theta1*Xt
Here z2 is the output after matrix multiplication, and Xt is the transpose of X.
The matrix multiplication process:
$$ \begin{bmatrix} 0.1 & 0.2 & 0.3 \\ 0.4 & 0.5 & 0.6 \\ \end{bmatrix} * \begin{bmatrix} 1 \\ 0.85 \\ 0.25 \\ \end{bmatrix} $$ $$ = \begin{bmatrix} 0.1*1 + 0.2*0.85 + 0.3*0.25 \\ 0.4*1 + 0.5*0.85 + 0.6*0.25 \\ \end{bmatrix} = \begin{bmatrix} 1.02 \\ 0.975 \\ \end{bmatrix} $$Let us say that we have applied a sigmoid activation after the input layer. Then we have to element-wise apply the sigmoid function to the elements in the z² matrix above. The sigmoid function is given by the following equation:
$$ f(x) = \frac{1}{1+e^{-x}} $$After the application of the activation function, we are left with a 2x1 matrix as shown below.
$$ a^{(2)} = \begin{bmatrix} 0.735 \\ 0.726 \\ \end{bmatrix} $$Here a(2) represents the output of the activation layer.
These outputs of the activation layer act as the inputs for the next or the final layer, which is the output layer. Let us initialize another random weights/parameters called Theta2 for the hidden layer. Each row in Theta2 represents the weights corresponding to the two neurons in the output layer.
$$ Theta_2 \begin{bmatrix} 0.5 & 0.4 & 0.3 \\ 0.2 & 0.5 & 0.1 \\ \end{bmatrix} $$After initializing the weights (Theta2), we will repeat the same process that we followed for the input layer. We will add a bias term for the inputs of the previous layer. The a(2) matrix looks like this after the addition of bias vectors:
$$ a^{(2)} = \begin{bmatrix} 1 \\ 0.735 \\ 0.726 \\ \end{bmatrix} $$Let us see how the neural network looks like after the addition of the bias unit:
Before we run our matrix multiplication to compute the final output z³, remember that before in z² calculation we had to transpose the input data a¹ to make it “line up” correctly for the matrix multiplication to result in the computations we wanted. Here, our matrices are already lined up the way we want, so there is no need to take the transpose of the a(2) matrix. To understand this clearly, ask yourself this question: “Which weights are being multiplied with what inputs?”. Now, let us perform the matrix multiplication:
z3 = Theta2*a(2) where z3 is the output matrix before the application of an activation function.
Here for the last layer, we will be multiplying a 2x3 with a 3x1 matrix, resulting in a 2x1 matrix of output hypotheses. The mathematical computation is shown below:
$$ \begin{bmatrix} 0.5 & 0.4 & 0.3 \\ 0.2 & 0.5 & 0.1 \\ \end{bmatrix} * \begin{bmatrix} 1 \\ 0.735 \\ 0.726 \\ \end{bmatrix} $$ $$ = \begin{bmatrix} 0.5*1 + 0.4*0.735 + 0.3*0.726 \\ 0.2*1 + 0.5*0.735 + 0.1*0.726 \\ \end{bmatrix} = \begin{bmatrix} 1.0118 \\ 0.6401 \\ \end{bmatrix} $$After this multiplication, before getting the output in the final layer, we apply an element-wise conversion using the sigmoid function on the z² matrix.
a3 = sigmoid(z3)
Where a3 denotes the final output matrix.$$ a^3 = \begin{bmatrix} 0.7333 \\ 0.6548 \\ \end{bmatrix} $$
The output of a sigmoid function is the probability of the given example belonging to a particular class. In the above representation, the first row represents the probability that the example belonging to Class 0 and the second row represents the probability of Class 1.
Conclusion
As you can see, the probability of the example belonging to a Class 1 is lesser than Class 0, which is incorrect and needs to be improved. Thus, we have not only understood the basic structure of a neuron but also a neural network. Further, we took a look at the forward propagation in a neural network with the help of an example.
In the next blog, we will discuss how to implement backward propagation to reduce the errors in the predictions. If you want to learn how to apply neural network in trading then please check our new course Neural Networks & Deep Learning In Trading by Dr. Ernest P. Chan.
Disclaimer: All investments and trading in the stock market involve risk. Any decisions to place trades in the financial markets, including trading in stock or options or other financial instruments is a personal decision that should only be made after thorough research, including a personal risk and financial assessment and the engagement of professional assistance to the extent you believe necessary. The trading strategies or related information mentioned in this article is for informational purposes only.

