
By Milind Paradkar & Chainika Thakar
Stock market forecasting has always been a subject of great interest for investors, analysts, and traders seeking to make informed investment decisions. One of the popular methods employed in time series analysis is the Autoregressive Integrated Moving Average (ARIMA) model. With its ability to capture trends, seasonality, and stationary behaviour, the ARIMA model has proven to be a powerful tool for forecasting stock returns.
In this blog, we will specifically delve into the widely-used ARIMA forecasting model, exploring how it can be applied to forecast stock returns. Moreover, this blog will take you through a detailed step-by-step procedure of implementing ARIMA modelling using the Python programming language.
The ARIMA (Autoregressive Integrated Moving Average) model is a handy tool for analysing and predicting sequential data.
It combines three important elements:
- AutoRegressive (AR) for looking at past observations
- Differencing (I or Integrated) for handling changes in data patterns and
- Moving average (MA) for considering error terms
All the concepts covered in this blog are taken from this Quantra learning track on Financial time series analysis for trading. You can take a Free Preview of the course.
Let us learn more about ARIMA model and forecasting stock prices using this model with this blog that covers:
- What is ARIMA model?
- What is ARIMA used for in the trading domain?
- What is time series analysis?
- What is a forecasting model in time series?
- Relevance of using ARIMA model with time series data in trading
- How to predict using ARIMA model with time series data in Python?
- Pros of using ARIMA model in trading
- Cons of using ARIMA model in trading
What is ARIMA model?
ARIMA stands for Autoregressive Integrated Moving Average. ARIMA is also known as the Box-Jenkins approach. Box and Jenkins claimed that non-stationary data can be made stationary by differencing the series, Yt. The general model for Yt is written as,
$$Y_t =ϕ1Y_t−1 + ϕ2Y_t−2…ϕpY_t−p +ϵ_t + θ1ϵ_t−1+ θ2ϵ_t−2 +…θqϵ_t−q$$Where Yt is the differenced time series value, ϕ and θ are unknown parameters and ϵ are independent identically distributed error terms with zero mean.
Here, Yt is expressed in terms of its past values and the current and past values of error terms.
This model is called Autoregressive Integrated Moving Average or ARIMA(p,d,q) of Yt. This is also termed as the ARIMA equation.

We will follow the steps enumerated below to build our model.
Step 1: Testing and Ensuring Stationarity
To model a time series with the Box-Jenkins approach, the series has to be stationary. A stationary time series means a time series without trend, one having a constant mean and variance over time, which makes it easy for predicting values.
Testing for stationarity - We test for stationarity using the Augmented Dickey-Fuller unit root test. The p-value resulting from the ADF test has to be less than 0.05 or 5% for a time series to be stationary. If the p-value is greater than 0.05 or 5%, you conclude that the time series has a unit root which means that it is a non-stationary process.
Differencing (d) – To convert a non-stationary process to a stationary process, we apply the differencing method. Differencing a time series means finding the differences between consecutive values of a time series data. The differenced values form a new time series dataset which can be tested to uncover new correlations or other interesting statistical properties.
We can apply the differencing method consecutively more than once, giving rise to the "first order differencing", "second order differencing", etc. This how each order differencing works:
- First-order differencing (d=1): This involves subtracting each observation from its preceding observation. It eliminates a linear trend from the data.
- Second-order differencing (d=2): If the first-differenced series is still non-stationary, a second-order differencing can be applied to remove any remaining trend or seasonality.
Hence, the purpose of a higher order differencing is to make the time series data completely stationary.
We apply the appropriate differencing order (d) to make a time series stationary before we can proceed to the next step.
Step 2: Identification of p and q
Since 'd' or differencing has been applied in the last step, in this step, we identify the appropriate 'p' order of Autoregressive (AR) model and 'q' order of Moving average (MA) model processes by using the Autocorrelation function (ACF) and Partial Autocorrelation function (PACF).
Identifying the p order of AR model
For AR models, the ACF will dampen exponentially and the PACF will be used to identify the order (p) of the AR model. If we have one significant spike at lag 1 on the PACF, then we have an AR model of the order 1, i.e. AR(1). If we have significant spikes at lag 1, 2, and 3 on the PACF, then we have an AR model of the order 3, i.e. AR(3).
Identifying the q order of MA model
For MA models, the PACF will dampen exponentially and the ACF plot will be used to identify the order of the MA process. If we have one significant spike at lag 1 on the ACF, then we have an MA model of the order 1, i.e. MA(1). If we have significant spikes at lag 1, 2, and 3 on the ACF, then we have an MA model of the order 3, i.e. MA(3).
Step 3: Estimation and Forecasting
Once we have determined the parameters (p,d,q) we estimate the accuracy of the ARIMA model on a training data set and then use the fitted model to forecast the values of the test data set using a forecasting function.
In the end, we cross-check whether our forecasted values are in line with the actual values.
What is ARIMA used for in the trading domain?
ARIMA (Autoregressive Integrated Moving Average) models have several applications in the realm of trading and financial markets. Here's how ARIMA is utilised in trading:
Stock price forecasting
Traders and investors often rely on ARIMA trading models to forecast stock prices or returns. These predictions aid in decision-making processes related to buying, selling, or holding stocks.
Volatility modelling
ARIMA trading models are valuable for modelling and predicting market volatility. Accurate volatility forecasts are crucial for risk management, option pricing, and optimising trading strategies.
Pairs trading
By leveraging ARIMA-based analysis, traders can identify and exploit relationships between pairs of securities. This approach helps uncover opportunities for executing profitable trading strategies based on mean-reverting behaviour.
Here is a short, educational video that explains the fundamentals of pairs trading strategy in about 3 minutes.
Market analysis
You can analyse historical market data, unveiling trends, cycles, and seasonality with the ARIMA trading model. These insights inform decision-making regarding optimal entry or exit points in the market.
Risk management
ARIMA trading models contribute to effective risk management strategies by estimating measures such as value at risk (VaR) or expected shortfall (ES) for portfolios. These measures assist traders in assessing and mitigating potential losses in different market scenarios.
By complementing the ARIMA model with other technical indicators, you can successfully forecast the stock prices.
What is time series analysis?
Time series analysis is a statistical technique used to examine and interpret data collected over a period of time. It focuses on studying the patterns, trends, and relationships within a sequence of chronologically ordered data points.
The main objective of time series analysis is to understand the underlying structure and characteristics of the data, make predictions for future values, and gain meaningful insights.
It involves visualising the data, calculating descriptive statistics, assessing stationarity, developing mathematical models, forecasting future values, and evaluating the accuracy of the models.
By analysing time series data, we can uncover important patterns, detect anomalies, and forecast future values. This helps in making informed decisions in the trading domain.
You can find out more about time series in the video below:
What is a forecasting model in time series?
Forecasting involves predicting future values based on historical data, either for a variable itself or by examining the relationship between variables. There are two main categories of forecasting approaches: qualitative and quantitative. In quantitative forecasting, we focus on time series data and apply statistical principles to predict future values.
Some popular techniques for time series forecasting include:
- Autoregressive Models (AR)
- Moving Average Models (MA)
- Seasonal Regression Models
- Distributed Lags Models
Autoregressive Models (AR)
These models assume that future values of a variable depend on its past values. By looking at the patterns and relationships within the variable's historical data, AR models can estimate future values.
Moving Average Models (MA)
MA models, on the other hand, consider the average of past error terms to forecast future values. They capture the random fluctuations or noise in the data.
Seasonal Regression Models
These models incorporate seasonal patterns into the forecasting process. They take into account variables that represent the seasonal effects observed in the data, helping us make predictions with periodicity in mind.
Distributed Lags Models
Distributed lags models analyse the relationship between a variable's current value and its lagged values. By considering the impact of past values on present and future values, these models offer insights into forecasting.
These techniques empower us to make predictions by leveraging patterns and relationships in the historical data. Time series forecasting plays a crucial role across various domains, such as finance, economics, and demand forecasting, assisting decision-making processes and enabling proactive planning.
Relevance of using ARIMA model with time series data in trading
The ARIMA (Autoregressive Integrated Moving Average) model holds significant relevance in trading when working with time series data. Here are some key reasons why the ARIMA model is commonly used in trading:
Capturing Time-dependent Patterns
Time series data in trading often exhibits temporal patterns, such as trends, seasonality, or cycles. The ARIMA trading model excels at capturing these patterns, allowing traders to identify potential opportunities and make informed decisions based on the underlying dynamics of the data.
Forecasting Price Movements
The ARIMA trading model can provide valuable insights into predicting future price movements in financial markets. By analysing historical price data, the model can generate forecasts that assist traders in identifying potential trends and making predictions about market direction.
Handling Non-stationarity
Non-stationarity refers to the presence of changing statistical properties over time. Many financial time series exhibit non-stationarity, which can hinder accurate predictions. The integration component in ARIMA (the "I" in ARIMA) helps transform non-stationary data into a stationary form, making it suitable for analysis and forecasting.
Incorporating Lagged Relationships
ARIMA trading models take into account the relationship between an observation and its lagged values, allowing traders to assess how past price movements impact future movements. This can provide insights into momentum, mean reversion, or other patterns that can guide trading strategies.
Modelling Volatility
The ARIMA trading model can be extended to incorporate volatility modelling, such as the GARCH (Generalised Autoregressive Conditional Heteroscedasticity) model. This extension helps traders estimate and predict volatility, which is crucial for risk management, option pricing, and designing trading strategies.
However, it's important to note that while the ARIMA trading model has its merits, it is not a one-size-fits-all solution for trading. Financial markets are complex and subject to various factors beyond time series patterns.
Traders often combine the ARIMA trading model with other techniques, such as technical indicators, fundamental analysis, to enhance forecasting accuracy and make well-informed trading decisions.
How to predict using ARIMA model with time series data in Python?
Let us see the steps for using the ARIMA model with time series data in the popular Python programming language.
Step 1: Import the required libraries
Import pandas, numpy, matplotlib, and statsmodels.
Step 2: Load and prepare the data
- Load the time series data into a pandas DataFrame.
- Preprocess the data if needed (e.g., handle missing values, convert data types).
- Set the index to the date or time column if applicable.
Step 3: Visualise the data and conduct the ADF test
- Plot the time series data to understand its patterns and trends.
The time series data will look like this:

- Conduct ADF test.
- If data is not stationary according to the ADF test, convert it into a stationary data.
The stationary data will be plotted and will be shown as below.

Step 4: Fit the ARIMA model and optimise the parameters of ARIMA (p, d, q)
- Determine the order of the ARIMA model (p, d, q) based on the data's characteristics.
- Create an ARIMA model object using ARIMA(data, order=(p, d, q)).
- Fit the model to the data using model_fit = model.fit().
- Remember to adjust the steps according to your specific dataset and requirements. It's essential to preprocess the data, validate the model's performance, and fine-tune the parameters (p, d, q) to improve the model's accuracy.
- This graph will look like this:

Step 5: Train the ARIMA model (p,d,q), forecast time series and evaluate model’s performance
- Train the ARIMA model, forecast the time series using return model_fit.forecast() and fit the model using print(model_fit.()).
- Analyse the model's performance and assess the coefficients.
- After evaluating the model’s performance it will look like the graph below.

Step 6: Create an ARIMA based trading strategy and analyse the strategy performance
- Now, you can create an ARIMA based trading strategy using the predictions made.
- After the strategy is created, you can analyse the performance of the strategy.
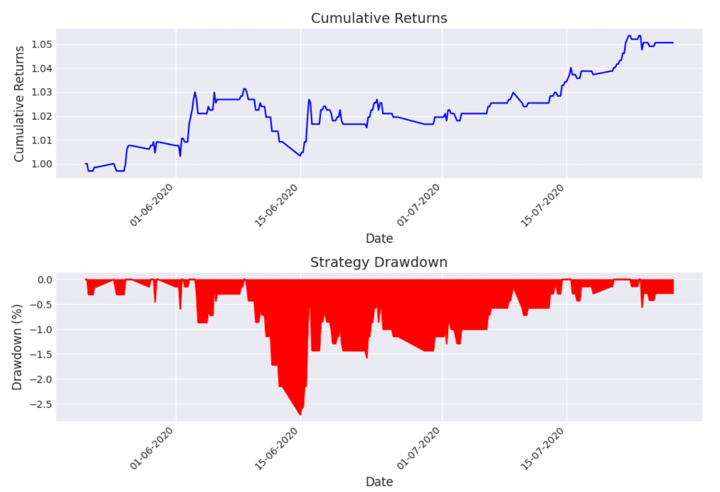
- The output will give you Sharpe Ratio, cumulative return and the maximum drawdown.
- The strategy performance will look like this as the plotted graph.
You can explore the full Python code for using the ARIMA model with time series data for predicting stock prices in the Section 18, Unit 9, Unit 11 and Unit 15 of the course titled Financial time series analysis for trading. These units consist of examples that explain the use of ARIMA models with all the parameters and real-time data.
Unit 9 will get you started for covering the basics of the ARIMA model with Python.
Unit 11 will consist of the entire Python code for the steps mentioned above.
Unit 15 will help you find the best fit ARIMA model.
Pros of using ARIMA model in trading
- Captures Time-dependent Patterns: The ARIMA model is effective at capturing trends, seasonality, and other temporal patterns in time series data, providing valuable insights into market behaviour.
- Proven Methodology: ARIMA is a well-established and widely used modelling technique in time series analysis, with a solid foundation in statistics. It has been successfully applied in various domains, including trading.
- Interpretability: ARIMA models provide interpretable results, allowing traders to understand the relationship between past and future price movements and make informed decisions based on the model's coefficients and statistical measures.
- Handles Non-stationarity: The ARIMA model's integration component (the "I" in ARIMA) helps transform non-stationary data into stationary form, addressing one of the challenges often encountered in financial time series analysis.
Cons of using ARIMA model in trading
- Limited Complexity: ARIMA models assume linear relationships and may struggle to capture complex or nonlinear patterns in financial markets. They might not fully capture sudden changes or rare events that can significantly impact prices.
- Data Quality and Assumptions: ARIMA models require high-quality data and rely on assumptions such as stationarity and normality. Violations of these assumptions can affect the model's accuracy and reliability.
- Limited Incorporation of External Factors: ARIMA models primarily focus on historical price data and may not readily incorporate external factors such as news events, economic indicators, or market sentiment that can influence price movements.
- Short-term Focus: ARIMA models tend to be better suited for short-term forecasting rather than long-term predictions. They may struggle to capture longer-term trends or shifts in market dynamics.
Conclusion
In trading, ARIMA models are employed to analyse historical price patterns, identify trends, and detect potential turning points in stock prices. These models can help traders anticipate market movements, assess risk, and optimise their investment strategies. By leveraging the statistical properties of time series data, ARIMA enables traders to make informed decisions based on a thorough understanding of market dynamics.
If you wish to explore more about using the ARIMA model for forecasting stock returns, you can explore our course on Financial time series analysis for trading. This is the perfect course to understand the concepts of Time Series Analysis and implement them in live trading markets. Starting from basic AR and MA models, to advanced models like ARIMA, SARIMA, ARCH and GARCH, this course covers it all.
Note: The original post has been revamped on 18th August 2023 for accuracy, and recentness.
Disclaimer: All data and information provided in this article are for informational purposes only. QuantInsti® makes no representations as to accuracy, completeness, currentness, suitability, or validity of any information in this article and will not be liable for any errors, omissions, or delays in this information or any losses, injuries, or damages arising from its display or use. All information is provided on an as-is basis.

